
Neural Language Model Story Completion: A Comparative Analysis
Tools Used
- Models
- DistilGPT-2
- GPT-2
- BART-base
- Evaluation Metrics
- ROUGE scores (ROUGE-1, ROUGE-2, ROUGE-L)
- BLEU scores
- Perplexity
- Datasets
As I approached the final phase of my Master’s in Human Language Technology, I wanted to tackle a project that would demonstrate both my technical implementation skills and my understanding of fundamental questions in natural language generation. The challenge I set for myself was to build a comprehensive evaluation framework that could fairly compare different neural language models on their ability to generate coherent, contextually appropriate story endings. What emerged was not just a technical exercise, but a deep exploration into the trade-offs between model efficiency, fluency, and semantic coherence that define modern NLP.
Project Genesis and Motivation
The inspiration for this project came from my fascination with narrative understanding and how machines can not only comprehend stories but continue them in ways that feel natural and satisfying to human readers. I chose to focus on the ROCStories dataset, which presents a particularly interesting challenge: given the first four sentences of a five-sentence story, can a language model generate an appropriate conclusion? This task requires understanding narrative structure, character motivation, causal relationships, and stylistic consistency–all fundamental aspects of human language comprehension.
I decided to compare three distinct models that represented different points on the efficiency-performance spectrum: DistilGPT-2 (a compressed, efficient model), GPT-2 (the standard baseline), and BART-base (a sequence-to-sequence model with different training objectives). My hypothesis was that each would exhibit unique strengths and weaknesses that would reveal important insights about the nature of story completion as a task.
Technical Architecture and Design Decisions
Building the evaluation framework required careful consideration of how to fairly compare models with fundamentally different architectures. I designed a StoryEvaluator class that could seamlessly handle both autoregressive models (the GPT variants) and encoder-decoder models (BART) while maintaining consistent evaluation criteria across all three.
One of my most important design decisions was implementing comprehensive error handling throughout the pipeline. During initial testing, I encountered numerous edge cases, such as empty generations, tokenization failures, and memory issues with longer sequences. Rather than simply catching and ignoring these errors, I built robust fallback mechanisms that would provide meaningful default values while logging the issues for later analysis. This attention to error handling proved crucial when processing the full 1000-story sample size, as it ensured that no single failure would compromise the entire evaluation run.
The generation parameters required particular tuning. I settled on a temperature of 0.7 with sampling enabled, which provided a balance between creativity and coherence. The maximum token limit of 30 for new generation was chosen after extensive experimentation. Too few tokens resulted in incomplete thoughts, while too many led to rambling continuations that strayed from the narrative focus.
Evaluation Methodology and Metrics
I implemented a multi-faceted evaluation approach that measured both content quality and linguistic fluency. For content quality, I used ROUGE scores (1, 2, and L variants) and BLEU scores to quantify how well the generated endings matched the reference conclusions. These metrics, while imperfect, provided standardized ways to measure semantic overlap and n-gram similarity.
More interesting to me was the perplexity analysis I implemented. I calculated perplexity for both the generated text and the target text using each model’s own scoring function. This dual measurement allowed me to assess not just how “natural” the generated text sounded according to the model, but also how well each model could predict the human-written reference endings. The implementation of this required careful attention to sequence length limitations and proper attention mask handling, technical details that significantly impacted the reliability of the results.
Results and Discoveries
The results revealed fascinating patterns that challenged some of my initial assumptions. GPT-2 slightly outperformed DistilGPT-2 on content similarity metrics (ROUGE and BLEU), which was expected given its larger parameter count. However, the perplexity results told a more nuanced story. DistilGPT-2 achieved dramatically better perplexity on its generated text (36,541 vs. 112 for GPT-2), suggesting that while its outputs might be less similar to human references, they were more consistent with its own learned language patterns.
The most surprising results came from BART-base. Its content similarity scores were dramatically lower than both GPT variants (0.0025 ROUGE-1 compared to ~0.13 for the GPT models), but it achieved near-perfect perplexity scores of approximately 1.0 for both generated and target text. This pattern initially puzzled me until I realized it likely indicated that BART was generating very short, highly confident outputs that didn’t capture the semantic richness of the reference endings but were linguistically perfect according to its own internal model.
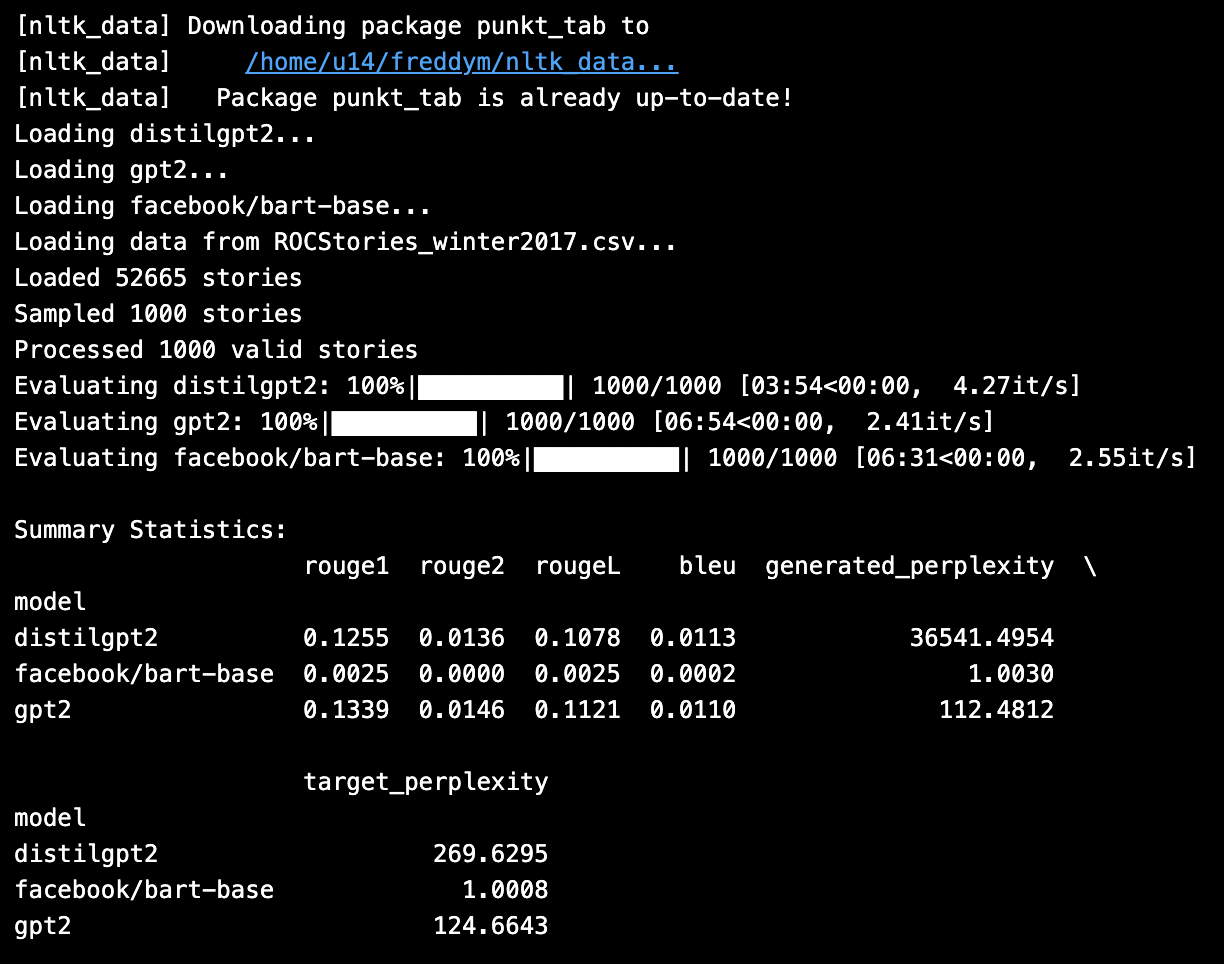
This discovery led me to a deeper understanding of the fundamental differences between autoregressive and sequence-to-sequence architectures in story completion tasks. BART, trained with a denoising objective, seemed to prioritize linguistic certainty over semantic expansion, while the GPT models, trained on next-token prediction, were more willing to take creative risks that sometimes paid off in better semantic similarity.
Technical Challenges and Problem-Solving
A major challenge I encountered was ensuring fair comparison across different tokenizers and model architectures. Each model had different special tokens, different context length limitations, and different optimal generation strategies. I addressed this by normalizing the input preprocessing while preserving each model’s unique characteristics during generation.
The perplexity calculation proved particularly tricky for edge cases—empty generations, very short texts, and sequences exceeding the model’s maximum position embeddings. I implemented multiple fallback strategies, including dynamic sequence truncation and careful validation of token sequences before passing them to the models.
Broader Implications and Insights
This project illuminated several important themes in modern NLP that extend beyond story completion. The trade-off between efficiency and performance, exemplified by the DistilGPT-2 vs. GPT-2 comparison, reflects ongoing industry debates about model compression and deployment. My results suggest that for applications where fluency matters more than exact semantic matching, smaller models might be preferable despite lower similarity scores.
The BART results highlighted how training objectives fundamentally shape model behavior. BART’s encoder-decoder architecture and denoising training led it to prioritize linguistic confidence over creative expansion, which might make it more suitable for tasks requiring precise, constrained generation rather than open-ended creativity.
Perhaps most importantly, this project reinforced the importance of multi-metric evaluation in NLP. Relying solely on ROUGE or BLEU scores would have painted an incomplete picture of model performance. The perplexity measurements revealed aspects of model behavior that content similarity metrics completely missed, suggesting that comprehensive evaluation requires considering both what models generate and how confident they are in their generations.
Reflection and Future Direction
Looking back on this project, I’m proud of both the technical implementation and the insights it generated. The modular architecture I built could easily be extended to evaluate additional models or incorporate new metrics. The comprehensive error handling and logging systems I implemented demonstrated the importance of robust engineering practices in research code.
If I were to continue this work, I would be particularly interested in exploring human evaluation of the generated endings. While automated metrics provide valuable standardized measurements, human judgment of narrative coherence, satisfaction, and creativity would add crucial dimensions to the analysis. I would also want to investigate the relationship between perplexity and human preference more deeply. Does lower perplexity always correlate with better human ratings?
This project encapsulated my journey through the Human Language Technology program: starting with fundamental questions about language and meaning, translating them into rigorous technical implementations, and discovering that the most interesting insights often emerge from the interplay between different measurement approaches. It demonstrated that meaningful NLP research requires not just technical skill, but careful experimental design and thoughtful interpretation of complex, sometimes contradictory results.