
RAG Evaluation and Chat Assistant Optimization
Tools Used
- LLMs, Rerankers, & Embedding Models (mostly utilizing Hugging Face)
- Qwen2.5:7B as well as other sizes
- GPT-4o as well as other models
- cross-encoder/ms-marco-MiniLM-L2-v2 as well as models with more layers
- sentence-transformers/all-MiniLM-L6-v2
- avsolatorio/GIST-all-MiniLM-L6-v2
- BAAI/bge-small-en-v1.5 as well as other sizes
- Evaluation Metrics
- Recall
- Precision
- F1
- MRR
- Semantic Similarity
- Semantic Faithfulness
- Semantic Relevance
- General Correctness
- Datasets
The primary objective of my internship at View Systems was to develop and maintain a comprehensive Retrieval-Augmented Generation (RAG) evaluation pipeline for their LLM Assistant product. The company sought to determine optimal configuration parameters for individual users based on their specific data characteristics and use cases. This required architecting an external RAG pipeline independent of the user interface to enable large-scale performance testing and optimization. I collaborated directly with Founder and CEO Joel Christner and Co-founder and Senior Member of Technical Staff Blake Martz throughout this initiative.
A Brief Introduction to View Systems
View Systems is an AI startup focused on delivering on-premises LLM Assistant solutions that enable organizations to use large language models while maintaining complete data sovereignty. Their core product allows users to deploy AI capabilities locally with their proprietary data, eliminating the need to transmit sensitive information to external services. The company also offers a secure SaaS alternative for organizations preferring cloud-based deployment while maintaining stringent security standards.
As a lean startup organization, View Systems operated with remarkable efficiency—I was among twelve employees participating in weekly company-wide meetings, which included the entire development team. The team’s accomplishments were particularly impressive given their size, successfully launching their beta product in early December 2024, midway through my internship.
Onboarding & Initial Implementation
My onboarding period involved establishing the development environment and familiarizing myself with View Systems’ existing API architecture and development workflows. Under the guidance of my supervisor Blake Martz, I initially focused on constructing a foundational RAG pipeline with essential evaluation capabilities.
Through systematic research and implementation, I developed a baseline evaluation framework incorporating fundamental NLP metrics including recall, precision, and F1 scores. Given that View Systems had not previously employed an NLP specialist, I provided technical guidance to the development team on these core evaluation methodologies and their implications for system performance assessment. I subsequently expanded the evaluation to include advanced metrics such as semantic similarity, faithfulness measures, and mean reciprocal rank, creating a more comprehensive performance analysis framework.
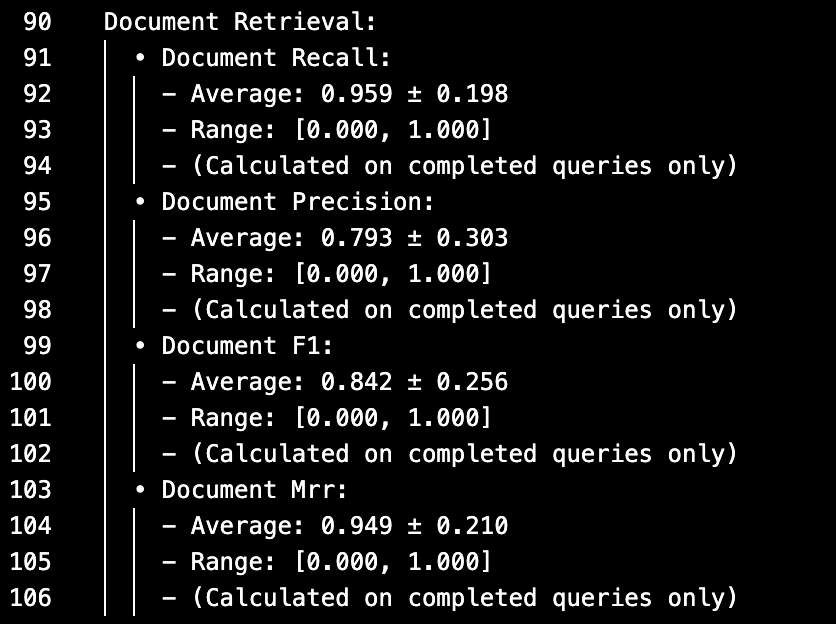
Integration & Optimization
The subsequent development phase involved intensive collaboration with Blake to transition from theoretical framework to production implementation. This represented my first opportunity to apply academic knowledge at a professional level, though it presented numerous technical challenges requiring meticulous attention to architectural details and system integration complexities.
This process revealed the sometimes stark differences between acadamic theory and actual production in professional settings. I needed to ensure that the evaluation pipeline could maintain consistent performance under varying load conditions and provide reliable metrics across different data distributions. This required implementing robust error handling and standardized logging mechanisms to track system performance.
I initiated utilizing the Stanford Question Answering Dataset (SQuAD) as the primary evaluation benchmark. SQuAD is comprised of Wikipedia articles and corresponding question-answer pairs, which was perfect for testing the retrieval of their RAG pipeline. The choice of SQuAD was strategic, as its established ground truth answers provide reliable standards for measuring retrieval accuracy and answer quality. I further incorporated SQuADShifts, which has alternate datasets from sources such as Reddit, Amazon reviews, and New York Times articles and comments. The consistent formatting across these datasets enabled efficient cross-domain evaluation with minimal preprocessing requirements, facilitating robust assessment across diverse data sources.
The dataset integration process required careful consideration of data preprocessing pipelines to ensure fair comparison across different domains. I developed formatting procedures that preserved the unique characteristics of each data source while maintaining consistency in evaluation methods. This preprocessing framework became a crucial component of the overall evaluation system, enabling seemless switching between datasets during optimization cycles.
Performance Optimization and Model Selection
I conducted extensive systematic testing runs, typically processing approximately 10,000 queries per evaluation cycle. My optimization methodology involved iterative single-variable adjustment to identify optimal system configurations for both retrieval accuracy and response quality. This systematic approach ensured that performance improvements could be attributed to specific parameter changes rather than random variation. Initial optimization focused on core system parameters including maximum concurrency levels, max token allocation per retrieved chunk, reranking topK values, and generation model prompt engineering.
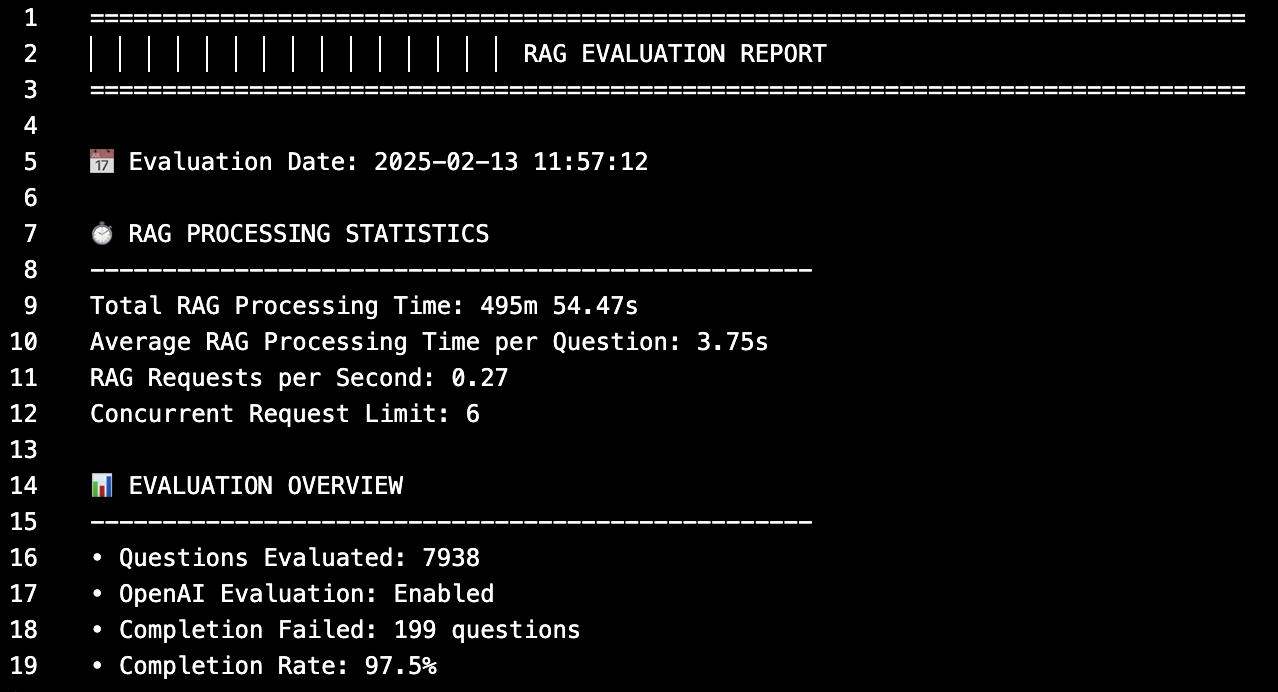
The reranking topK parameter revealed the most interesting insights during this phase about the relationship between initial retrieval quality and reranking effectiveness. I discovered that while higher topK values generally improved final accuracy, the gains were usually marginal and certainly diminished beyond certain thresholds. This suggested that effective initial retrieval was more important than extensive reranking for overall system performance.
Upon reaching optimized settings through parameter tuning, I shifted focus to core model optimization, systematically evaluating alternative architectures for the generation, embedding, and reranking components. While generation model optimization built upon previous experimentation, the embedding and reranking model selection required comprehensive research to balance performance improvements against processing latency constraints.
Final Architecture and Outcomes
Through systematic evaluation using Hugging Face model repositories, I established an optimal configuration consisting of Qwen2.5:7B for text generation, BAAI/bge-small-en-v1.5 for embedding computation, and cross-encoder/ms-marco-MiniLM-L2-V2 for reranking operations.
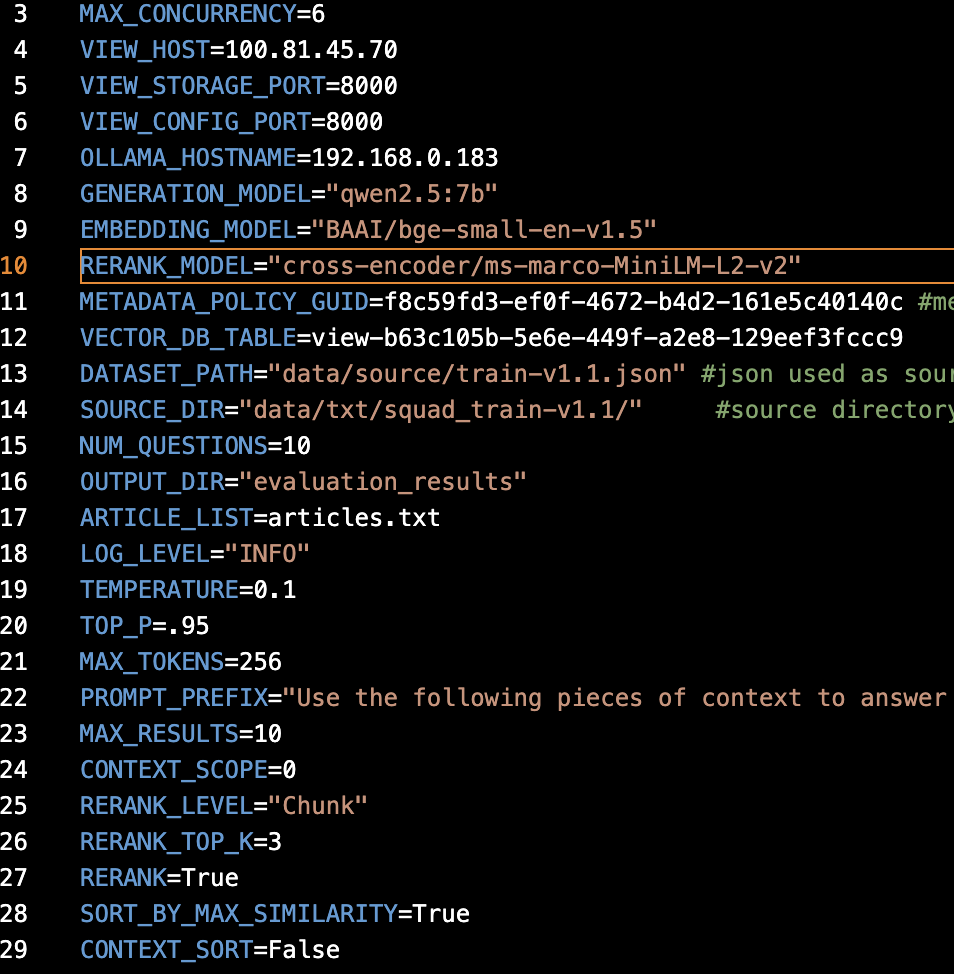
The reranking model selection yielded particularly noteworthy results. Despite my expectations, the 2-layer MiniLM-L2-V2 model outperformed the 6-layer L6-V2 variant, achieving superior accuracy metrics despite modest latency increases. This counterintuitive finding led to our decision to prioritize performance over processing speed for the reranking component.
The embedding model transition from sentence-transformers/all-MiniLM-L6-v2 to the BGE architecture delivered the most significant retrieval performance improvements with negligible computational overhead. Generation model optimization, after extensive experimentation with multiple architectures, ultimately confirmed that the initial model selection provided optimal performance for our specific use case, reinforcing the value of principled baseline establishment.
Impact and Departure
This project successfully established View Systems’ first comprehensive RAG evaluation infrastructure, enabling data-driven optimization decisions and providing the foundation for user-specific parameter customization. The evaluation pipeline I developed continues to serve as the primary performance assessment tool for their LLM Assistant product, directly supporting their go-to-market strategy and customer onboarding processes.
The optimization insights I generated through systemic testing informed not only immediate product improvements but could also improve long-term architectural decisions. Furthermore, the diverse dataset evaluation approach I implemented demonstrated the robustness of optimized configurations across different domains, hopefully providing View Systems with confidence in their ability to serve customers across diverse industries and use cases. My work contributed directly to View Systems’ product, providing the performance validation and optimization capabilities to show product viability to early customers.